
2026年5月28日、29日、ヒューマノイドロボットの研究者・開発企業・投資家が一堂に会する国際カンファレンス「Humanoids Summit Tokyo 2026」が開催された。本稿が注目するのは、技術系の4講演。汎用の頭脳を掲げるGoogle DeepMindとフィールドAI、頭脳に動く身体を与えるディズニー・リサーチ、そして技術を量産へと運ぶユニツリー。それぞれ立場は異なるが、プログラムする時代から、学習し汎化する時代へ、そして量産への道筋も示された。
言語が動作になる――Google DeepMind「Gemini Robotics」が示す汎用の頭脳
Day2の基調講演に登壇したGoogle DeepMindのロボティクス部門責任者、カロライナ・パラダ氏は、基盤モデルGeminiに「行動(Action)」を新たなモダリティとして加えることで実現する次世代ロボットのビジョンを語った。
これまでロボットは製造や物流の現場で活躍してきたが、その多くは特定タスクをこなすようプログラムされ、環境や扱う物体について多くの前提条件を必要としていた。「環境・タスク・周囲のオブジェクトが少しでも変われば、ゼロからやり直しになる」とパラダ氏は指摘。新用途の展開に数カ月を要することも珍しくないという。

この脆弱性を克服する鍵が、視覚言語行動モデル「VLA(Vision-Language-Action)」だ。パラダ氏はこれを「Geminiに新しいモダリティとしてアクションを追加するもの」と説明。Geminiがテキストや画像を生成するように、器用なロボット動作を生成できるという。
実例として挙げられたのは、前提知識のないロボットに「スラムダンクして」と指示したケース。ロボットはGeminiの広範な世界理解を活かし、0.25秒以内にボールをリングへ入れるべきと判断した。
2025年に発表された「Gemini Robotics」は、この思想を体現した最先端のVLAだ。進化版「Gemini Robotics 1.5」では、エージェント機能が追加された。実世界のタスクは複数ステップを要するため、ゴミ仕分けデモでは、ロボットがインターネットで分別ルールを検索し、テーブル上の物体と照合しながら各物体の行き先を判断する様子が示された。
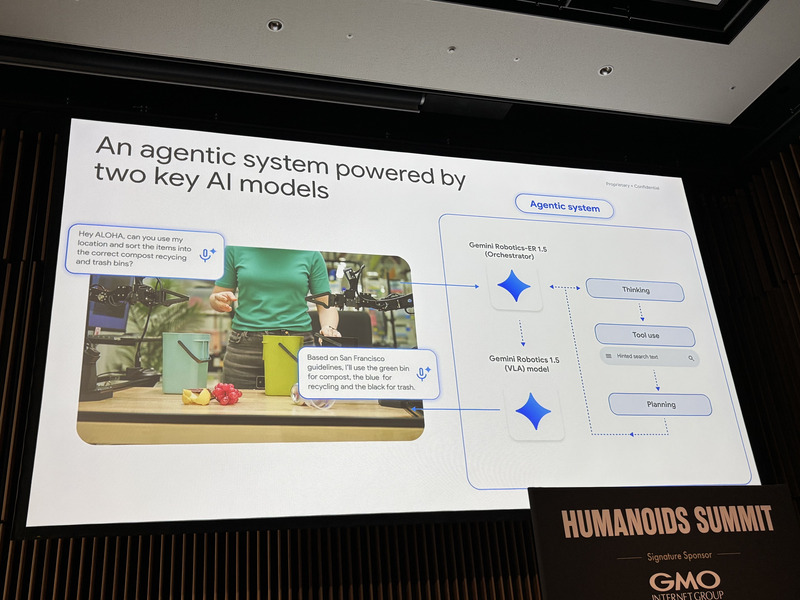
この高レベル推論を担うのが、身体的推論に特化した「Gemini Robotics ER(Embodied Reasoning)」だ。製造現場のアナログ計器読み取りでは、ノイズや汚れのあるゲージを読む精度を、テストにおいて20%台から約93%まで向上させたという。
さらにモデルは記憶と思考能力を持ち、言語と運動がより深く統合される。現実世界への展開に向け、Boston Dynamics、Agility Robotics、Unitree Roboticsとパートナーシップを結ぶ。テスタープログラムには日本原子力研究開発機構(JAEA)、パナソニック、トヨタ、Tronなどが参加する。
パラダ氏は「世界はあらゆる種類のロボットが豊かに存在し、人間の中で稼働し、産業の現場で稼働し、すべてがより知的で、より適応性が高く、より多目的で、より安全な環境になると信じています」と締めくくった。
もうひとつの頭脳、産業現場へ――フィールドAIの「保証される自律」
「汎用ロボットの頭脳:産業用AIの新時代」と題して講演を行ったのが、フィールドAI創業者兼CEOのアリ・アガ(Ali Agha)氏だ。同社が提供する、頭脳を内蔵した箱型のデバイスは、すべてがエッジで動く。バックパックサイズの小型機からヒューマノイド、数トンの車両まで、すでに30以上のプラットフォームに統合されている。
アガ氏は、フィジカルAIにはデータの軸とアーキテクチャの軸があるとし、同社はアーキテクチャ軸に大きく注力していると語った。物理法則と不確実性の定量化をニューラルネットワークに焼き込むことで、安全性と確実性を担保する。その成果が、必要なデータ量を減らしハルシネーションを低減する新しいモデル群「Field Foundation Models(FFM)」だ。

フィールドAIが狙う領域は、「DDD」――Dirty(汚い)、Dull(退屈)、Dangerous(危険)であり、製造、建設、データセンター、都市オペレーションといった産業に絞る。なかでも主要な業種の一つが建設だ。講演では、約3年協業してきた鹿島建設の例も示された。
建設現場では、技術者がデータ収集に多くの時間を費やす。そこで自律ロボットを投入し、デジタルツインの作成や点検を担わせ、技術者を本来の業務へ解放する。
アガ氏が強調したのは、同社のモデルが「接続なし、事前の地図なし、GPSなし」で作業をこなす点だ。地図化も教示用ルートの整備も不要で、現場へそのまま送り込める。

脚付き、車輪付き、飛行型と計11台のロボットが未知の環境へ入っていくデモも示された。地図もGPSも事前の軌道もないなか、ロボットたちは自ら探索し、役割を分担する。塵や霧にはサーマルカメラを備えた機体を、縦坑にはドローンを、不揃いな階段には脚付きロボットを――システムが自律的に差配する。同社はいま、この発想をマルチヒューマノイドへと押し進めているという。